1. AWS 데이터베이스 서비스
- AWS에서는 사용자 요구 사항에 따라 관계형 데이터베이스 서비스, 키-값 데이터베이스, 인-메모리 데이터베이스 등 다양한 데이터베이스 서비스를 제공한다.
1) Amazon RDS
Amazon RDS(Relational Database Service)
- 클라우드 환경에서 관계형 데이터베이스를 간편하게 설정하고 운영할 수 있는 서비스
- Amazon Aurora, PostgreSQl, MariaDB, Oracle Database, SQL Server 등 관게형 데이터베이스 엔진을 선택할 수 있다.
- Amazon RDS는 관계형 데이터베이스 모델 유형으로, 테이블 구조에 행(row)과 열(column)로 구성된다.
- 관계형 데이터베이스 엔진을 사용하기 때문에 SQL 언어 기반으로 데이터베이스를 손쉽게 제어할 수 있다.
- 사용 편의성이 높고, 모니터링 및 지표와 이벤트 알람을 이용하여 높은 관리 효율성을 보장하며, 비용도 상대적으로 매우 저렴하다. 또한 간편한 복제 기능을 이용하여 워크로드의 가용성과 확장성을 확보할 수 있다.
2) Amazon RDS 데이터 복제
Multi-AZ 복제 방식
- 기본적으로 액티브- 스탠바이(active-standby) 형태로 동작한다.
- Primary DB가 액티브(활성) 상태이며, 보조의 standby Replica가 스탠바이(대기) 상태이다.
- Primary DB에 문제가 발생하면 Standby Replica를 Primary DB로 승격하여 동적으로 유지한다.
- 이런 Multi-AZ 복제 방식은 데이터 정합성을 유지하는 것이 가장 중요하다. 데이터 정합성이란 데이터가 서로 일관되게 일치하는 것으로, 이를 위해 동기식 복제(synchronous replica)로 다른 가용 영역에 있는 데이터베이스와 데이터를 동기화한다.
Read Replica 복제 방식
- 원본 데이터를 Primary DB에 두고, 읽기 전용의 복제 데이터를 Read Replica 데이터베이스에 생성하여 유지한다.
- 읽기 전용 복제 데이터가 있는 Read Replica 데이터베이스는 확장이 가능하며, 데이터 읽기 처리 속도를 높일 수 있다.
- Amazon RDS는 최대 다섯 개의 Read Replica 데이터베이스를 복제할 수 있으며, 다른 리전까지 Read Replica 데이터베이스를 가질 수 있다.
3) Amazon Aurora
- AWS 자체의 클라우드 데이터베이스 엔진
- 엔터프라이즈 수준의 관계형 데이터베이스 엔진으로 안정적이고 고성능의 데이터베이스 처리가 가능하다. 또한 오픈 소스를 기반으로 다른 관계형 데이터베이스와 호환성이 우수하며, 비용 효율이 높다는 장점이 있다.
- 이런 Amazon Aurora 데이터베이스 엔진은 Amazon RDS에서 관리하며 프로비저닝, 패치, 백업, 복원, 장애 복구 등 작업을 수행한다.
Amazon Aurora 복제 방식
- Amazon Aurora 데이터베이스 엔진은 다른 관계형 데이터베이스 엔진보다 스토리지 내결함성이 우수하다.
ex)
MySQL 데이터베이스 엔진은 데이터베이스 인스턴스에 EBS 스토리지가 연결되어 서로 다른 가용 영역으로 동기식 복제가 된다. 반면 Amazon Aurora 데이터베이스 엔진은 공유 스토리지를 통해 최소 세 개의 가용 영역에서 두 개씩 총 여섯 개의 복제 데이터를 가지고 있어 더욱 안정적으로 서비스할 수 있다.
4) Amazon Dynamo DB
- Amazon Dynamo DB는 비관계형 데이터베이스로, 키-값(key-value) 메소드를 사용하는 키-값 데이터베이스이다.
- 키를 데이터의 고유한 식별자로 사용하고, 값은 유형의 제한이 없어 단순한 개체(entity)뿐 아니라 복잡한 집합체까지 무엇이든 가능한 비정형 데이터를 입력할 수 있다.
- 별도 서버를 구축하지 않고 운영되는 서버리스(serverless)로 동작하기 때문에 서버에 대한 프로비저닝, 패치, 소프트웨어 설치가 필요없고 용량에 따라 테이블을 자동으로 확장 및 축소해서 관리 편의성이 높다.
5) Amazon ElastiCache
- Amazon ElastiCache는 인-메모리 데이터베이스로, 데이터를 메모리에 저장하는 형태로 동작한다.
- 데이터가 메모리상에 위치하여 데이터를 빠르게 처리할 수 있다는 장점이 있지만, 데이터 양이 많다면 데이터 처리가 느려질 수 있기 때문에 대용량 데이터에는 적합하지 않고 주로 데이터를 빠르게 자주 접근해야 할 때 사용한다.
- Memcached 방식과 Redis 방식 두 가지로 구분된다.
Amazon ElastiCache for Memcached
- Memcached는 보편적으로 사용하는 메모리 객체 캐싱 시스템으로, 인-매모리 데이터베이스 서비스이다.
- 자주 접근할 데이터를 메모리에 놓고 빠르게 처리할 수 있다.
Amazon ElastiCache for Redis
- Redis는 데이터베이스, 캐시, 메시지 브로커 및 대기열 용도로 사용되는 인-메모리 데이터베이스 서비스이다.
- 실시간 애플리케이션을 지원할 수 있도록 1밀리초 미만의 지연으로 빠른 데이터를 처리할 수 있다.
3. 웹 서버와 Amazon RDS 연동하기
실습 단계
- 실습을 위한 기본 인프라를 CloudFormation으로 배포
- Amazon RDS를 생성하고 웹 서버와 연동
- Amazon RDS의 고가용성을 위한 Multi-AZ를 구성하고 동작을 확인
- Amazon RDS의 성능 확장을 위한 Read Replica를 구성하고 동작을 확인
1) CloudFormation으로 기본 인프라 배포하기
- AWS 관리 콘솔에서 서비스 > 관리 및 거버넌스 > CloudFormation으로 들어가 스택 생성을 누른다.
- Amazon S3 URL에 URL을 입력하고 다음을 누른다.

- 스택 세부 정보 지정 페이지에서 다음과 같이 설정하고 다음을 누른다.
- 스택 이름에 'dblab' 입력
- KeyName은 사용자 키 페어 파일 선택
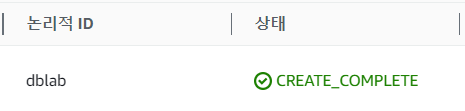
- AWS CloudFormation 기본 인프라를 배포하고 일정시간이 지나 스택 상태가 'CREATE_COMPLELTE'가 되면 모든 인프라 배포가 정상적으로 완료된다.
2) Amazon RDS를 생성하고 웹 서버와 연동하기
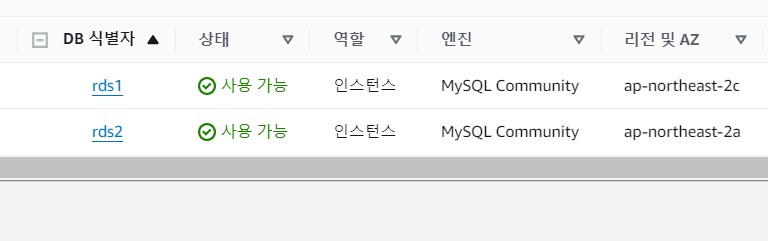
- 두 개의 Amazon RDS를 생성
- Amazon RDS1 데이터베이스를 생성하기 위해 AWS 관리 콘솔에서 서비스 > 데이터베이스 > RDS를 차례로 선택하고 대시보드에서 데이터베이스 생성을 누른다.
- RDS 데이터베이스 생성 페이지에서 다음과 같이 설정한다.
- [엔진 옵션] 엔진 유형은 MySQL 선택
- 템플릿은 개발/테스트 선택
- [가용성 및 내구성] 배포 옵션은 다중 AZ DB 인스턴스 선택
- [설정] DB 인스턴스 식별자에 'rds1' 입력
- 마스터 사용자 이름에 'root' 입력
- 마스터 암호와 암호 확인에 'qwe12345' 입력
- [인스턴스 구성] DB 인스턴스 클래스는 버스터블 클래스로 선택, '이전 세대 클래스 포함'에 체크한 후 db.t2.micro 선택
- [연결] Virtual Private Cloud(VPC)는 CH5-VPC 선택
- 기존 VPC 보안 그룹(방화벽)은 'default'를 제거한 후 dblab-CH6SG2-XXXX 선택
- [모니터링] 'Enhanced 모니터링 활성화'에 체크 해제
- 맨 아래쪽에 내려가 추가구성을 클릭하고 초기 데이터베이스 이름에 'sample' 입력
- DB 파라미터 그룹은 dblab-mydbparametergroup-XXXX 선택
- 백업 보존 기간은 35일 선택
- 마지막으로 맨 아래쪽에 있는 데이터베이스 생성 누르기
- RDS1 데이터베이스의 특징은 '다중 AZ DB 인스턴스'를 선택하여 Multi-AZ 기능을 활성화하였다. Multi-AZ 기능을 활성화하면 Primary DB와 Standby Replica가 생성되기 때문에 시간이 길어진다.
- RDS2 데이터베이스 생성
- [엔진 옵션] 엔진 유형은 MySQL 선택
- [템플릿] 프리 티어 선택
- [설정] DB 인스턴스 식별자에 'rds2' 입력
- 마스터 사용자 이름에 'root' 입력
- 마스터 암호와 암호화 학인에 'qwe12345' 입력
- [인스턴스 구성] DB 인스턴스 클래스는 버스터블 클래스 선택, '이전 세대 클래스 포함'에 체크한 후 db.t2.micro 선택
- [연결] Virtual Private Cloud(VPC)는 CH6-VPC 선택
- 기존 VPC 보안 그룹은 'default'를 제거한 후 dblab-CH6SG2-XXXX 선택
- 가용 영역은 ap-northeast-2a 선택
- 맨 아래쪽으로 내려가 추가구성을 클릭하고 초기 데이터베이스 이름에 'sample' 입력
- DB 파라미터 그룹은 dblab-mydbparametergroup-XXXX 선택
- 백업 보존 기간은 0일 선택
- 백업 기간은 기간 선택을 선택하고 '01:00 UTC', '0.5시간'으로 지정
- RDS2 데이터베이스의 특징은 'Multi-AZ 기능이 비활성화된' 상태로, 백업 보존 기간을 0일로 설정하여 '자동 백업 기능을 비활성화' 했다.
- 웹 서버(CH6-WebSrv) 및 Amazon RDS와 연동
- RDS1과 RDS2 데이터베이스의 엔드포인트 주소를 확인한다.
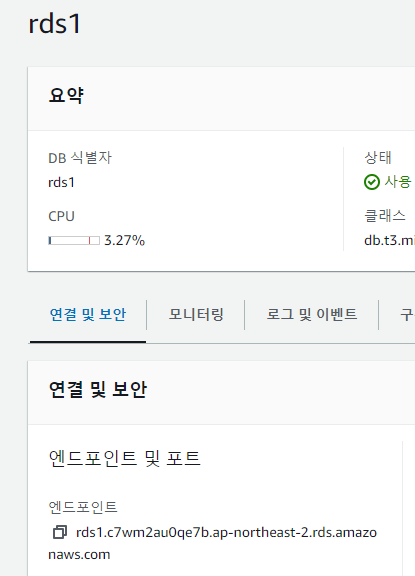
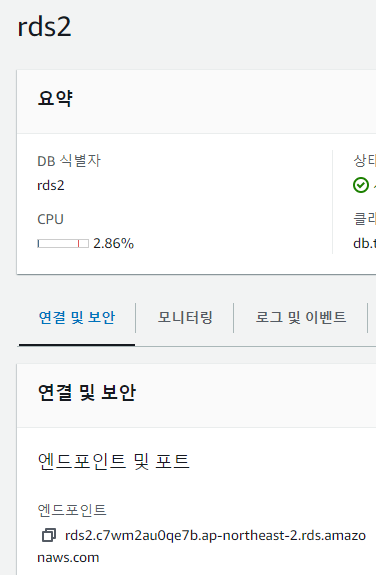
- CH6-WebSrc에 SSH로 접속하여 확인한 엔드포인트 주소를 변수로 선언한다.
# CH6-WebSrv의 SSH 터미널
# RDS1과 RDS2의 엔드포인트 주소를 변수로 선언(각자의 엔드포인트 주소로 입력)
RDS1=rds1 엔드포인트 주소
RDS2=rds2 엔드포인트 주소
# 선언된 변수 호출
echo $RDS1
echo $RDS2

- RDS1과 RDS2 데이터베이스에 MySQL 명령어로 접속하고 데이터베이스 정보를 확인한다.
- -h 옵션으로 데이터베이스 주소를 지정하고, -u 옵션으로 사용자 ID를 입력하며, -p 옵션으로 암호를 입력
# CH6-WebSrv의 SSH 터미널
# RDS1 데이터베이스에 접속(RDS2도 동일하게 수행)
mysql -h $RDS1 -uroot -pqwe12345
# 상태 정보와 데이터베이스 확인
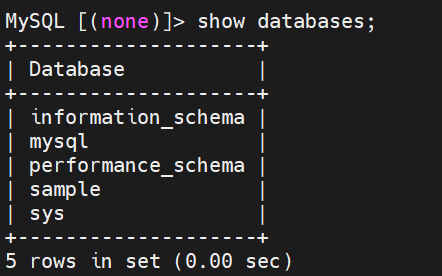
status;
show databases;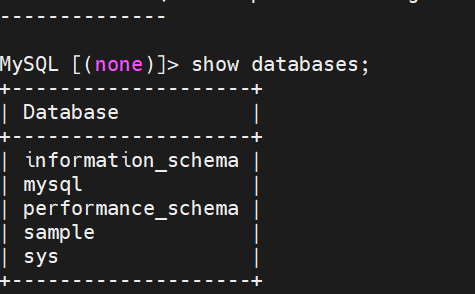
- CH6-WebSrv의 index.php 파일을 수정하여 RDS2 데이터베이스와 연동한다.
# CH6-WebSrv의 SSH 터미널
# index.php 파일의 상위 다섯 줄만 확인
head -5 /var/www/html/index.php

- index.php 파일에서 DB_SERVER 값은 임의로 설정되어 있어 데이터베이스 주소를 입력해야 한다. RDS2의 엔드포인트 주소를 해당 영역에 입력하기 위해 다음과 같이 명령어를 입력한다.
# CH6-WebSrv의 SSH 터미널
# index.php 파일의 DB_SERVER 값을 RDS2 엔드포인트 주소로 치환
sed -i "s/dbaddress/$RDS2/g" /var/www/html/index.php
# index.php 파일의 상위 두 줄만 확인
head -2 /var/www/html/index.php

- DB_SERVER 주소는 변수로 선언한 RDS2 엔드포인트 주소로 변환되어 CH6-WevSrv와 RDS2 데이터베이스 간 연동 환경을 구성한다.
- EC2 인스턴스(CH6-WebSrv)의 퍼블릭 주소를 입력하여 인터넷 웹 브라우저로 접속한 후 데이터를추가한다.
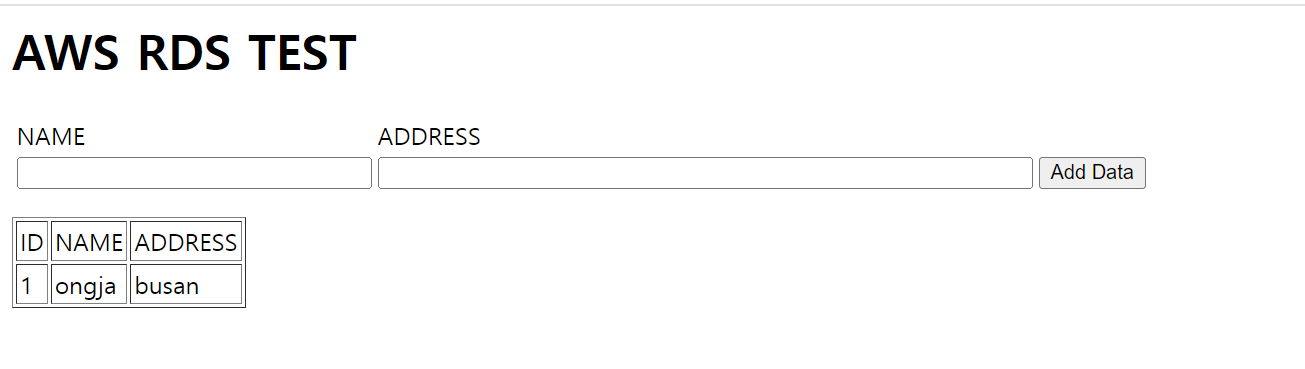
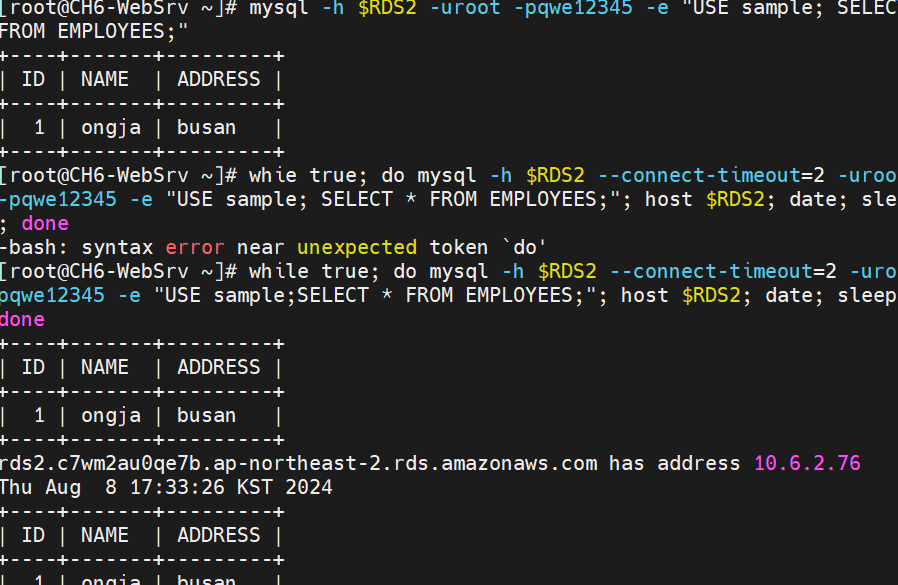
- CH6-WebSrv의 SSH 터미널에 접속하여 MySQL 명령어로 데이터베이스 테이블을 확인한다.
# CH6-WebSrv의 SSH 터미널
# RDS2의 데이터베이스 EMPLOYEES 테이블 확인(1회)
mysql -h $RDS2 -uroot -pqwe12345 -e "USE sample;SELECT * FROM EMPLOYEES;"
# RDS2의 데이터베이스 EMPLOYEES 테이블 확인(반복문)
while true; do mysql -h $RDS2 --connect-timeout=2 -uroot -pqwe12345 -e "USE sample;SELECT * FROM EMPLOYEES;"; host $RDS2; date; sleep 1; done
RDS2가 중지될 경우 동작 확인하기
- RDS2는 장애에 대한 페일오버(failover)(장애 극복 기능)를 수행할 수 없다.
- CH6-WebSrv의 SSH 터미널에 접속하여 MySQL 명령어로 데이터베이스 테이블을 확인하는 반복문을 수행한다.
# CH6-WebSrv의 SSH 터미널
# RDS2의 데이터베이스 EMPLOYEES 테이블 확인 스크립트(반복문)
. /db_sh/SELECT_TABLE_RDS2.sh
- RDS2를 선택한 후 작업 > 일시적으로 중지를 선택한다. 이때 버튼을 클릭하면 팝업창이 열리는데 '7일 후 DB 인스턴스가 자동으로 다시 시작하는 것에 동의합니다'에 체크한 후 일시적으로 중지를 클릭한다.

- 데이터베이스 테이블을 확인하는 반복문을 다시 확인한다. RDS2가 중지되어 데이터베이스 테이블 정보를 가져오지 못하고 있다.

- RDS2 데이터베이스는 단일로 동작하고 있기 때문에 중지되거나 재부팅이 발생하면 데이터베이스를 찾을 수 없어 문제가 발생한다.
3) Amazon RDS의 고가용성을 위한 Multi-AZ 동작 확인하기
- CH6-WebSrv를 Multi-AZ 기능이 활성화된 RDS1로 연결한다.
- CH5-WebSrv의 index.php 파일을 수정하여 RDS1 데이터베이스와 연동한다.
# CH6-WebSrv의 SSH 터미널
# index.php 파일의 DB_SERVER 값을 RDS1 엔드포인트 주소로 치환
sed -i "s/$RDS2/$RDS1/g" /var/www/html/index.php
# index.php 파일의 상위 두 줄만 확인
head -2 /var/www/html/index.php

- DB_SERVER 주소를 RDS1 엔드포인트 주소로 변환하여 CH6-WebSrv와 RDS1 데이터베이스 간 연동환경을 구성한다.
- RDS1 데이터베이스의 EMPLOYEES 테이블 정보를 확인한다.
# CH6-WebSrv의 SSH 터미널
# RDS1의 데이터베이스 EMPLOYEES 테이블 확인 스크립트(반복문)
. /db_sh/SELECT_TABLE_RDS1.sh
- 현재 RDS1은 EMPLOYEES 테이블이 없어 오류 메시지가 발생한다. 웹 서버의 웹 페이지에 접속하면 생성되지만 이번에는 명령어를 이용하여 테이블을 생성
# CH6-WEbSrv의 SSH 터미널
# EMPLOYEES 테이블 생성
mysql -h $RDS1 -uroot -pqwe12345 -e "USE sample;CREATE TABLE EMPLOYEES(ID int, NAME CHAR(20), ADDRESS CHAR(20));"
- INSERT 명령어로 RDS1의 EMPLOYEES 테이블에 데이터를 추가한다.
# CH6-WebSrv의 SSH 터미널
# EMPLOYEES 테이블에 데이터 추가
mysql -h $RDS1 -uroot -pqwe12345 -e "USE sample;INSERT INTO EMPLOYEES VALUES ('1', 'SON', 'UK');"
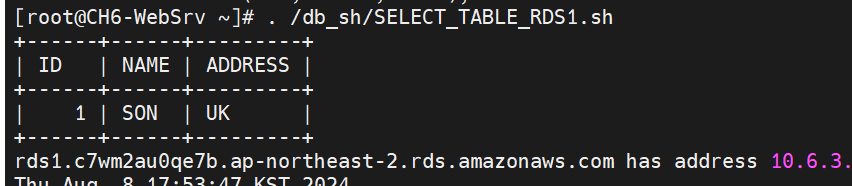
- RDS1은 Multi-AZ가 활성화되어 Primary DB와 Standby Replica는 서로 다른 가용 영역에 위치한다.
- Primary DB와 Standby Replica는 서로 동기화되어 테이블을 유지하며, Primary DB에 장애가 발생하면 Standby Replica와 Primary DB로 승격되어 페일오버를 수행할 수 있다.
- RDS1을 재부팅하기 위해 데이터베이스 메뉴에서 RDS1을 선택하고 작업 > 재부팅을 선택한다. 재부팅 창이 열리면 '장애 조치로 재부팅하겠습니까?'에 체크하고 확인을 누른다.
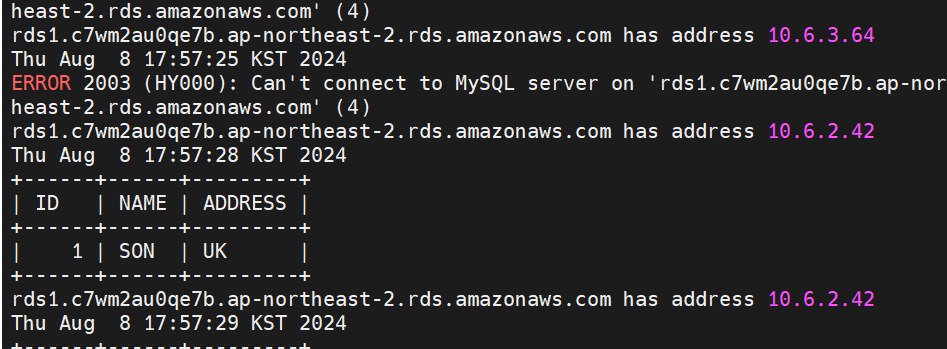
- RDS1의 IP 주소를 확인해 보면 최초 10.6.3.64에서 10.6.2.42로 변경된 것을 알수 있다. 이 의미는 Primary DB가 변경된 것으로 이해할 수 있다.
4) Amazon RDS의 성능을 확장하는 Read Replica 동작 확인하기
- Read Replica는 읽기 전용 데이터베이스인 Read Replica 데이터베이스를 복제하여 데이터 처리 성능을 높이는 기능이다.
- RDS2 데이터베이스의 Read Replica를 설정하기 위해 데이터베이스 메뉴에서 RDS2를 선택하고 작업 > 읽기 전용 복제본 생성을 선택한다.
- Read Replica의 제약 조건은 자동 백업 기능을 활성화 해야 한다는 것이다.
- RDS1의 Read Replica 설정으로 읽기 전용의 데이터베이스 복제본을 생성
- RDS1 데이터베이스의 Read Replica 설정을 위해 데이터베이스 메뉴에서 RDS1를 선택하고 작업 > 읽기 전용 복제본 생성을 선택
- DB 인스턴스의 읽기 전용 복제본 생성 페이지가 나타나면 다음과 같이 설정한다.
- [설정] DB 인스턴스 식별자는 'rds1-rr'로 입력
- 가장 아래쪽에 있는 읽기 전용 복제본 생성을 누른다.
- CH6-WebSrv에 SSH로 접속하여 RDS1-RR의 엔드포인트 주소를 변수로 선언
# CH6-WebSrv의 SSH 터미널
# RDS1-RR의 엔드포인트 주소를 변수로 선언
RDS1RR=엔드포인트 주소
# 선언된 변수 호출
echo $RDS1RR
- RDS1과 RDS1-RR의 데이터베이스 EMPLOYEES 테이블을 확인한다.
# CH6-WebSrv의 SSH 터미널
# RDS1의 EMPLOYEES 테이블 확인
mysql -h $RDS1 -uroot -pqwe12345 -e "USE sample;SELECT * FROM EMPLOYEES;"
# RDS1-RR의 EMPLOYEES 테이블 확인
mysql -h $RDS1RR -uroot -pqwe12345 -e "USE sample;SELECT * FROM EMPLOYEES;"
-RDS1-RR은 RDS1의 복제본 데이터베이스이기 때문에 서로 동일한 테이블을 유지한다.
- MySQL INSERT 명령어를 이용하여 RDS1의 EMPLOYEES 테이블에 데이터를 추가한다.
# CH6-WebSrv의 SSH 터미널
# RDS1의 EMPLOYEES 테이블에 데이터 추가
mysql -h $RDS1 -uroot -pqwe12345 -e "USE sample;INSERT INTO EMPLOYEES VALUES ('2', 'Park', 'Suwon');"
- RDS1과 RDS1-RR의 데이터베이스 EMPLOYEES 테이블을 확인한다.
# CH6-WebSrv의 SSH 터미널
# RDS1의 EMPLOYEES 테이블 확인
mysql -h $RDS1 -uroot -pqwe12345 -e "USE sample;SELECT * FROM EMPLOYEES;"
# RDS1-RR의 EMPLOYEES 테이블 확인
mysql -h $RDS1RR -uroot -pqwe12345 -e "USE sample;SELECT * FROM EMPLOYEES;"
- RDS1은 Primary DB로 읽기와 쓰기가 모두 가능하며, RDS1-RR은 RDS1의 복제본 데이터베이스로 데이터를 동기화해서 읽을 수만 있는 데이터베이스이다.
'AWS' 카테고리의 다른 글
| [AWS 교과서] 8장 AWS IAM 서비스 (0) | 2024.08.13 |
|---|---|
| [AWS 교과서] 7장 AWS 고급 네트워킹 서비스 (0) | 2024.08.11 |
| [AWS 교과서] 5장 AWS 스토리지 서비스 (0) | 2024.08.02 |
| [AWS 교과서] 4장 AWS 부하 분산 서비스 (0) | 2024.08.01 |
| [AWS 교과서] 3장 AWS 네트워킹 서비스 (0) | 2024.07.31 |



