파이썬 모듈
- 파이썬 코드를 논리적으로 묶어서 관리하고 사용할 수 있도록 하는 것
- 모듈의 단위는 파이썬 파일(.py)
- 모듈의 호출은 import 모듈명으로 모듈을 가져 올 수 있음
- as(alias)를 활용해 긴 모듈명을 줄일 수 있음
import keyword as K
print(K.kwlist)
-> keyword라는 모듈을 as K, 즉 K라는 이름으로 호출했고, keyword 모듈 내 kwlist를 출력하는 코드
https://docs.python.org/3/py-modindex.html
Python Module Index — Python 3.12.4 documentation
numbers Numeric abstract base classes (Complex, Real, Integral, etc.).
docs.python.org
- help("modules") 명령어로 현재 사용할 수 있는 (설치된) 모듈의 목록 확인 가능
- Anaconda로 파이썬을 설치한 경우 아나콘다 폴더 내 lib 폴더에 모듈을 직접 확인 가능
자주 사용되는 모듈
1) os 모듈
- 운영체제와 상호작용하기 위한 수십가지 함수들을 제공
2) time 모듈
3) random 모듈
- 다양한 랜덤 관련 함수들을 제공
import random
print(random.random())
print(random.randint(1,5))
4) math 모듈
- 수학적으로 복잡한 연산이 필요한 경우, 수학과 관련된 함수들을 제공
통계를 위한 모듈
- 데이터 분석 통계
: numpy, pandas, matplotlib, SciPy, Scikit
- 인공지능
: Tensorflow, PyTorch, Keras
- 데이터 분석
:BeautifulSoup, selenium
Numpy
- 수학 및 과학 연산을 위한 모듈
- n차원 배열로 행렬 연산을 빠르고 편리하게 할 수 있는 장점
Matplotlib
- 대표적인 파이썬의 시각화 모듈로 막대 그래프, 꺽은선 그래프, 파이 그래프, 산점도 그래프 등 다양한 형태의 그래프를 기를 수 있음
Pandas
- 데이터 분석을 위해 사용되는 모듈로 파이썬에서 손쉽게 데이터를 가져와서 정제 및 분석할 수 있음
Scikit
- Numpy, SciPy 및 matplotlib를 기반으로 분류, 회귀, 클러스터링 및 차원 감소를 비롯한 기계 학습 및 통계 모델링을 위한 효율적은 도구가 많이 포함되어 있음
데이터 다루기
requests 모듈
- 파이썬에서 HTTP와 관련된 모듈로, HTTP 요청과 응답에 관련된 다양한 기능을 보다 쉽게 사용 할 수 있도록 도와줌
pip install requests
- get 함수를 활용하여 원하는 홈페이지의 페이지 소스를 요청하여 받아 올 수 있다.
- get 함수로 특정 홈페이지 url의 정보를 요청하여 받은 다음 text 명령어를 통해 해당 홈페이지의 페이지 소스를 문자열 형태로 출력할 수 있다.
import requests
url = "https://www.naver.com"
req = requests.get(url)
print(req.text)

import requests
URL = 'https://search.naver.com/search.naver'
params = {'query' : 'aa'}
response = requests.get(URL,params=params)
print(response.status_code)
print(response.text)
bs4 모듈
- 홈페이지 내 데이터를 쉽게 추출할 수 있도록 도와주는 파이썬 외부 모듈
pip install bs4- 웹 문서 내 수많은 HTML 태그들을 파서를 활용해 사용하기 편한 파이썬 객체로 만들어 제공
- 모듈 내 BeautifulSoup() 클래스에 HTML 문서와 파서를 전달하여 분석 결과를 객체에 저장
BeautifulSoup("<a></p>","html.parser")
## <a><a/>
- BeautifulSoup은 HTML을 파싱하여 구조화하는 모듈로 홈페이지 소스를 가져올 수는 없기 때문에 주로 requests 모듈과 함께 사용
- requests 모듈로 웹 문서를 텍스트로 가져온 뒤, BeautifulSoup 모듈로 분석
import requests
from bs4 import BeautifulSoup
req = requests.get("https://www.naver.com")
html = req.text
soup = BeautifulSoup(html,"html.parser")
print(soup.title)
print(soup.title.name)
print(soup.title.string)

re 모듈
- 정규 표현식을 사용할 수 있도록 re(Regular Expression) 모듈을 제공
- 정규 표현식은 특정한 규칙을 가진 문자열을 표현하기 위해 사용하는 형식으로 주로 문자열의 검색 및 치환에 활용
- 정규 표현식을 잘 활용하면 데이터를 손쉽게 분석, 가공하여 원하는 데이터를 출력할 수 있음
import re
text = ('111<head>안녕하세요</head>22')
body = re.search('<head.*/head>',text)
body = body.group()
print(body)

"""#기본패턴
a,T,4 등 과 같은 하나 하나의 character들은 정확히 해당 문자와 일치
ex) 패턴 test는 test 문자열과 일치
대소문자의 경우 기본적으로 구별가능하나, 구별하지 않도록 설정 가능
몇몇 문자들은 예외로서 특별한 의미를 가짐
. ^ $ * + ? {} [] \ () 등등
.(온점) : 하나의 character와 일치 (단, new line(엔터)은 제외한다.)
\w - 문자 character와 일치 [a-zA-Z0-9_]
\s - 공백 문자와 일치
\t, \n, \r - 각각 tab, new line, return을 의미
\d - 숫자 character와 일치 [0-9]
^ 는 시작, $는 끝을 의미
\가 붙으면 스페셜한 의미는 사라짐.
예를 들어, '\. '는 ' . '자체를 의미하고 '\\'는 '\'를 의미한다.
참고 : 링크 (파이썬 문서 - re 모듈)"""
통계 및 데이터 분석을 위한 Numpy, Pandas
Numpy
- 행렬이나 일반적으로 대규모 다차원 배열을 쉽게 처리할 수 있도록 도와주는 파이썬의 외부 모듈
- anaconda 설치 시 함께 설치되며, pip install Numpy로도 설치할 수 있음
- 기본적으로 array라는 자료형을 사용하며, 뜻 그대로 행렬의 개념으로 생각하면 됨
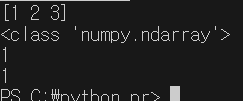
import numpy as np
data = [1,2,3]
arr = np.array(data)
print(arr)
print(type(arr))
print(data[0])
print(arr[0])
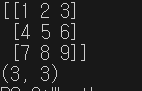
import numpy as np
data=[[1,2,3],[4,5,6],[7,8,9]]
arr = np.array(data)
print(arr)
print(arr.shape)
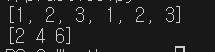
- 리스트 자료형과 다르게 Numpy는 행렬의 형태로 행렬 연산이 가능
import numpy as np
data = [1,2,3]
arr = np.array(data)
print(data+data)
print(arr+arr)
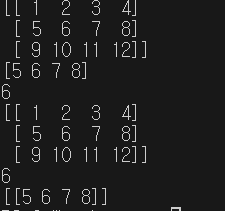
import numpy as np
data = [[1,2,3,4],[5,6,7,8],[9,10,11,12]]
arr = np.array(data)
print(arr)
print(arr[1])
print(arr[1][1])
print(arr[:3])
print(arr[1,1])
print(arr[1:2])
- 통계와 관련된 sum(합), mean(평균), std(표준편차), min,max,argmin 등의 함수를 제공
import numpy as np
data = [[1,2,3,4],[5,6,7,8],[9,10,11,12]]
arr = np.array(data)
print(np.sum(arr))
print(np.mean(arr))
print(np.std(arr))
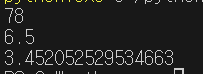
- 행렬을 손쉽게 정의하기 위한 함수들도 제공
- zeros() : 입력받은 크기만큼의 값이 0인 행렬 생성
- ones() : 입력받은 크기만큼 값이 1인 행렬 생성
- arrange() : 입력받은 크기만큼 값이 1씩 증가하는 1차원 행렬 생성
import numpy as np
data = np.zeros((5,5))
print(data)
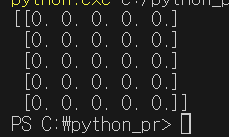
import numpy as np
data = np.ones((5,5))
print(data)

import numpy as np
data = np.arange(5)
print(data)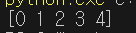
Pandas
- 행과 열로 이루어진 데이터를 쉽게 다룰 수 있도록 도와주는 데이터분석 전용 외부 모듈
- anaconda 설치 시 함께 설치되며, pip install Pandas로도 설치할 수 있ㄷ음
- 기본적으로 Series와 DataFrame이라는 자료형을 사용하며, 빅데이터 분석에 높은 성능을 보여줌
- Series 자료형은 인덱스와 값을 가지고 있음
-> 별도로 인덱스, 값을 출력할 수 있으며, 정의할 때 인덱스를 따로 정해줄 수 있음
import pandas as pd
data = pd.Series([4,7,-5,3])
print(data)
print(type(data))
print(data.values)
print(data.index)

import pandas as pd
data = pd.Series([4,7,-5,3],index=['d','b','a','c'])
print(data)
print(type(data))

- 파이썬의 딕셔너리 자료형을 Series 자료형으로 만들 수 있음, 딕셔너리의 키 == Series의 인덱스
import pandas as pd
data = pd.Series({'a':1,'b':2,'c':3})
print(data)
print(type(data))

- Data Frame은 행과 열로 이루어진 데이터셋으로 파이썬의 딕셔너리 자료형 또는 Numpy의 array로 정의할 수 있음
-> 시리즈는 인덱스, 값으로만 이루어져 있지만 데이터프레임은 행과 열로 이루어짐
import pandas as pd
data1 = pd.Series({'a':[1,2,3],'b':[4,5,6],'c':[7,8,9]})
data2 = pd.DataFrame({'a':[1,2,3],'b':[4,5,6],'c':[7,8,9]})
print(data1)
print(type(data1))
print()
print(data2)
print(type(data2))

- 행 방향의 순서는 index, 열 방향의 순서는 columns 명령어로 확인할 수 있음
import pandas as pd
data = pd.DataFrame({'a':[1,2,3],'b':[4,5,6],'c':[7,8,9]})
print(data)
print(data.index)
print(data.columns)
- 각각 인덱스에 이름을 설정할 수 있음
import pandas as pd
data = pd.DataFrame({'a':[1,2,3],'b':[4,5,6],'c':[7,8,9]})
data.index.name = 'aaa'
data.columns.name = 'bbb'
print(data)
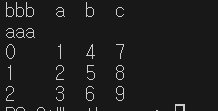
- 각 데이터를 손쉽게 선택, 수정, 삽입 등을 할 수 있다.
import pandas as pd
data = pd.DataFrame({'a':[1,2,3],'b':[4,5,6],'c':[7,8,9]})
print(data)
print(data['a'])
data['a'] = [0,0,0]
print(data)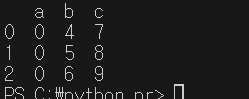
Data Frame의 다양한 함수
1) describe()
- data frame에서 계산 가능한 값들에 대해 다양한 계산의 결과를 간략하게 보여줌
import pandas as pd
data = pd.DataFrame({'a':[1,2,3],'b':[4,5,6],'c':[7,8,9]})
print(data)
print(data.describe())

2) sum()
- 합계를 보여주며, axis 옵션으로 행, 열 기준을 변경할 수 있음
- axis = 0이 각 열의 합, axis = 1이 각 행의 합을 나타내고, 특정 열의 합 또한 계산 가능
import pandas as pd
data = pd.DataFrame({'a':[1,2,3],'b':[4,5,6],'c':[7,8,9]})
print(data.sum())
print(data.sum(axis=1))
print(data['a'].sum())

그외
- min,max, argmin, argmax, mean, median, std,var,unique
실습 - Pandas 예제
https://github.com/jjiiiwooo/ML.git
GitHub - jjiiiwooo/ML
Contribute to jjiiiwooo/ML development by creating an account on GitHub.
github.com
'기타 > 글로컬청년취업사관학교' 카테고리의 다른 글
| [TlL] 240620 (0) | 2024.06.20 |
|---|---|
| [TlL] 240619 (0) | 2024.06.19 |
| [TlL] 240617 (0) | 2024.06.17 |
| [TIL] 240614 (0) | 2024.06.14 |
| [TlL] 240613 (0) | 2024.06.13 |



