1. 가중치 시각화
- 합성곱 층은 여러 개의 필터를 사용해 이미지에서 특징을 학습한다.
- 각 필터는 커널이라 부르는 가중치와 절편을 가지고 있다.
- 가중치는 입력 이미지의 2차원 영역에 적용되어 어떤 특징을 두드러지게 표현하는 역할을 한다.

- 이 필터의 가운데 곡선 부분의 가중치 값은 높고 그 외부분의 가중치 값은 낮을 것이다. 이렇게 해야 둥근 모서리가 있는 입력과 곱해져서 큰 출력을 만들기 때문이다.
- 앞서 만든 모델이 어떤 가중치를 학습했는지 확인하기 위해 체크포인트 파일을 읽기
from tensorflow import keras
# 코랩에서 실행하는 경우에는 다음 명령을 실행하여 best-cnn-model.h5 파일을 다운로드받아 사용
!wget https://github.com/rickiepark/hg-mldl/raw/master/best-cnn-model.h5
- 케라스 모델에 추가한 층은 layers 속성에 저장되어 있다. 이 속성은 파이썬 리스트이다.
model.layers
- 층의 가중치와 절편은 층의 weights 속성에 저장되어 있다.
- weights도 파이썬 리스트이다.
- layers 속성의 첫 번째 원소를 선택해 weights의 첫 번째 원소(가중치)와 두 번째 원소(절편)의 크기를 출력
conv = model.layers[0]
print(conv.weights[0].shape, conv.weights[1].shape)
- 커널 크기를 (3,3)으로 지정했고 이 합성곱 층에 전달되는 입력의 깊이가 1이므로 실제 커널 크기가 (3,3,1)이다.
또 필터 개수가 32개이므로 weights의 첫 번째 원소인 가중치의 크기는 (3,3,1,32)가 되었다.
- weights의 두 번째 원소는 절편의 개수를 나타낸다. 필터마다 1개의 절편이 있으므로 (32,)크기가 된다.
- weights 속성은 텐서플로의 다차원 배열인 Tensor 클래스의 객체이다. 여기서는 다루기 쉽도록 numpy() 메서드를 사용해 넘파이 배열로 변환
- 그 다음 가중치 배열의 평균과 표준편차를 넘파이 mean() 메서드와 std() 메서드로 계산
conv_weights = conv.weights[0].numpy()
print(conv_weights.mean(), conv_weights.std())
- 이 가중치의 평균값은 0에 가깝고 표준편차는 0.27 정도이다.
- 가중치가 어떤 분포를 가졌는지 직관적으로 이해하기 쉽도록 히스토그램 그리기
- 맷플롯립의 hist() 함수에는 히스토그램을 그리기 위해 1차원 배열로 전달해야 한다. 이를 위해 넘파이 reshape 메서드로 conv_weights 배열을 1개의 열이 있는 배열로 변환
import matplotlib.pyplot as plt
plt.hist(conv_weights.reshape(-1, 1))
plt.xlabel('weight')
plt.ylabel('count')
plt.show()
- 32개의 커널을 16개씩 두 줄에 출력
- 맷플롯립의 subplots() 함수를 사용해 32개의 그래프 영역을 만들고 순서대로 커널을 출력
fig, axs = plt.subplots(2, 16, figsize=(15,2))
for i in range(2):
for j in range(16):
axs[i, j].imshow(conv_weights[:,:,0,i*16 + j], vmin=-0.5, vmax=0.5)
axs[i, j].axis('off')
plt.show()

- conv_weights[:,:.0,0]에서 conv_weights[:,:,0,31]까지 출력한다.
- imshow() 함수는 배열에 있는 최댓값과 최솟값을 사용해 픽셀의 강도를 표현한다. 어떤 절댓값으로 기준을 정해서 픽셀의 강도를 나타내야 비교하기 좋다. 이를 위해 위 코드에서 vmin과 vmax로 맷플롯립의 컬러맵(colormap)으로 표현할 범위를 지정
- 훈련하지 않은 빈 합성곱 신경망 만들기
- Sequential 클래스로 모델을 만들고 Conv2D 층을 하나 추가
no_training_model = keras.Sequential()
no_training_model.add(keras.layers.Conv2D(32, kernel_size=3, activation='relu',
padding='same', input_shape=(28,28,1)))
- 이 모델의 첫 번째 층의 가중치를 no_training_conv 변수에 저장
no_training_conv = no_training_model.layers[0]
print(no_training_conv.weights[0].shape)
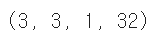
- 이 가중치의 크기도 앞서 그래프로 출력한 가중치와 같다. 동일하게 (3,3) 커널을 가진 필터를 32개 사용했기 때문이다.
- 이 가중치의 평균과 표준편차 확인
no_training_weights = no_training_conv.weights[0].numpy()
print(no_training_weights.mean(), no_training_weights.std())
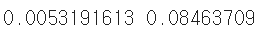
- 평균은 이전과 동일하게 0에 가깝지만 표준편차는 이전과 달리 매우 작다.
plt.hist(no_training_weights.reshape(-1, 1))
plt.xlabel('weight')
plt.ylabel('count')
plt.show()
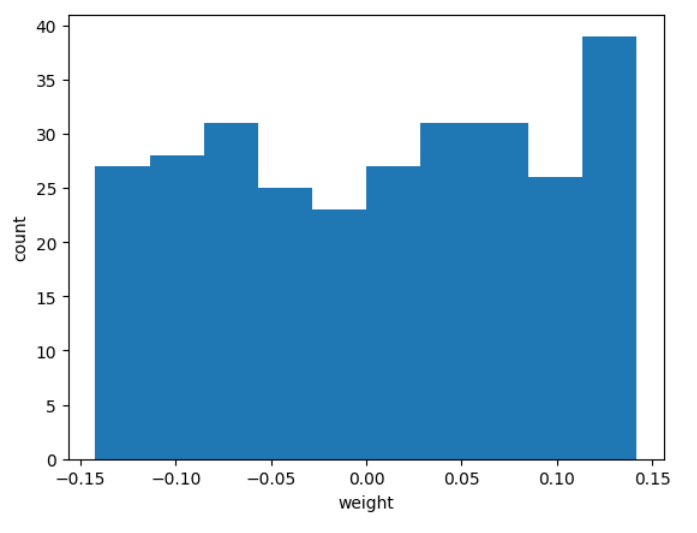
- 대부분의 가중치가 -0.15 ~0.15 사이에 있고 비교적 고른 분포를 보인다. 이런 이유는 텐서플로가 신경망의 가중치를 처음 초기화할 때 균등 분포에서 랜덤하게 값을 선택하기 때문이다.
fig, axs = plt.subplots(2, 16, figsize=(15,2))
for i in range(2):
for j in range(16):
axs[i, j].imshow(no_training_weights[:,:,0,i*16 + j], vmin=-0.5, vmax=0.5)
axs[i, j].axis('off')
plt.show()

- 히스토그램에서 보았듯이 전체적으로 가중치가 밋밋하게 초기화되었다.
- 훈련이 끝난 이전 가중치와 비교하면 합성곱 신경망이 패션 MNIST 데이터셋의 분류 정확도를 높이기 위해 유용한 패턴을 학습했다는 사실을 눈치챌 수 있다.
2. 함수형 API
- 딥러닝에서 좀 더 복잡한 모델을 만들 때는 Sequential 클래스를 사용하기에 어렵다. 대신 함수형 API(functional API)를 사용한다.
- 함수형 API는 케라스의 Model 클래스를 사용하여 모델을 만든다 .
ex)
- Dense층 2개로 이루어진 완전 연결 신경망을 함수형 API로 구현
dense1 = keras.layers.Dense(100,activation='sigmoid')
dense2 = keras.layers.Dense(10,activation='softmax')
- 이 객체를 Sequential 클래스 객체의 add() 메서드에 전달할 수 있지만 다음과 같이 함수처럼 호출할 수도 있다.
hidden = dense1(inputs)
- 케라스의 층은 객체를 함수처럼 호출했을 때 적절히 동작할 수 있도록 미리 준비해 놓았다.
- 입력값 inputs를 Dense층에 통과시킨 후 출력값 hidden을 만들어 준다.
- 두 번째 층을 호출한다. 이때는 첫 번째 층의 출력을 입력으로 사용한다.
outputs = dense2(hidden)
- 그 다음 inputs와 outputs을 Model 클래스로 연결해주면 된다.
model = keras.Model(inputs, outputs)
- Sequential 클래스는 InputLayer 클래스를 자동으로 추가하고 호출해 주지만 Model 클래스에서는 우리가 수동으로 만들어서 호출해야 한다. 바로 inputs가 InputLayer 클래스의 출력값이 되어야 한다.
- 케라스는 InputLayer 클래스 객체를 쉽게 다룰 수 잇지만 Input() 함수를 별도로 제공한다.
- 입력의 크기를 지정하는 shape 매개변수와 함께 이 함수를 호출하면 InputLayer 클래스 객체를 만들어 출력을 반환해준다.
inputs = keras.Input(shape=(784,))
- 특성 맵 시각화를 만드는 데 함수형 API가 필요한 이유?
- 우리가 필요한 것은 첫 번째 Conv2D의 출력이다.
- model 객체의 입력과 Conv2D의 출력을 알 수 있다면 이 둘을 연결하여 새로운 모델을 얻을 수 있다.
- 첫 번째 층의 출력은 Conv2D 객체의 output 속성에서 얻을 수 있다.
- model 객체의 입력은 model.input으로 얻을 수 있다.
print(model.input)
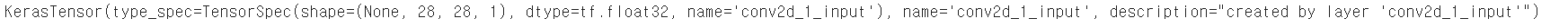
- model.input과 model.layers[0],output을 연결하는 새로운 conv_acti 모델을 만들 수있다.
conv_acti = keras.Model(model.input, model.layers[0].output)
3. 특성 맵 시각화
- 합성곱 신경망 학습을 시각화하는 두 번째 방법은 합성곱 층에서 출력된 특성 맵을 그려보는 것
- 케라스로 패션 MNIST 데이터셋을 읽은 후 훈련 세트에 있는 첫 번째 샘플을 그려보는 것
(train_input, train_target), (test_input, test_target)
= keras.datasets.fashion_mnist.load_data()
plt.imshow(train_input[0], cmap='gray_r')
plt.show()
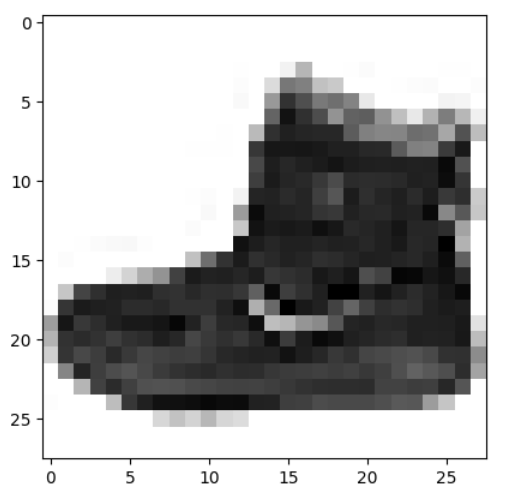
- 이 샘플을 conv_acti 모델에 주입하여 Conv2D 층이 만드는 특성 맵을 출력
- predict() 메서드는 항상 입력의 첫 번째 차원이 배치 차원일 것으로 기대한다. 하나의 샘플을 전달하더라도 꼭 첫 번째 차원을 유지해야 한다. 이를 위해 슬라이싱 연산자를 사용해 첫 번째 샘플을 선택한다.
inputs = train_input[0:1].reshape(-1, 28, 28, 1)/255.0
feature_maps = conv_acti.predict(inputs)
- conv_acti.predict() 메서드가 출력한 feature_maps의 크기를 확인
print(feature_maps.shape)
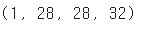
- 세임 패딩과 32개의 필터를 사용한 합성곱 층의 출력이므로 (28,28,32)이다.
- 맷플롯립의 imshow 함수로 이 특성 맵을 그리기. 총 32개의 특성 맵이 있으므로 4개의 행으로 나누어 그리기
fig, axs = plt.subplots(4, 8, figsize=(15,8))
for i in range(4):
for j in range(8):
axs[i, j].imshow(feature_maps[0,:,:,i*8 + j])
axs[i, j].axis('off')
plt.show()

- 이 특성맵은 32개의 필터로 인해 입력 이미지에서 강하게 활성화된 부분을 보여준다.
- 두 번째 합성곱 층이 만든 특성 맵도 같은 방식으로 확인할 수 있다.
- 먼저 model 객체의 입력과 두 번째 합성곱 층인 model.layers[2]의 출력을 연곃한 conv2_acti 모델을 만든다.
conv2_acti = keras.Model(model.input, model.layers[2].output)
- 첫 번째 샘플을 conv2_acti 모델의 predict() 메서드에 전달한다.
feature_maps = conv2_acti.predict(train_input[0:1].reshape(-1, 28, 28, 1)/255.0
- 첫 번째 풀링 층에서 가로세로 크기가 절반으로 줄었고, 두 번째 합성곱 층의 필터 개수는 64개이므로 feature_maps의 크기는 배치 차원을 제외하면 (14,14,64)일 것이다.
print(feature_maps.shape)
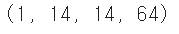
- 64개의 특성 맵을 8개씩 나누어 imshow() 함수로 그려보기
fig, axs = plt.subplots(8, 8, figsize=(12,12))
for i in range(8):
for j in range(8):
axs[i, j].imshow(feature_maps[0,:,:,i*8 + j])
axs[i, j].axis('off')
plt.show()

- 합성곱 신경망의 앞 부분에 있는 합성곱 층은 이미지의 시각적인 정보를 감지하고 뒤쪽에 있는 합성곱 층은 앞쪽에서 감지한 시갖거인 정보를 바탕으로 추상적인 정보를 학습한다고 볼 수 있다.
'데이터 > 머신러닝' 카테고리의 다른 글
| [혼공] ch 9. 텍스트를 위한 인공신경망 (0) | 2024.07.02 |
|---|---|
| [혼공] ch 8-2 합성곱 신경망을 사용한 이미지 분류 (1) | 2024.07.01 |
| [혼공] ch 8-1. 합성곱 신경망의 구성 요소 (0) | 2024.07.01 |
| [혼공] ch 7-3 신경망 모델 훈련 (0) | 2024.07.01 |
| [혼공] ch 7-2 심층 신경망 (0) | 2024.07.01 |



