1. 데이터 분석이란?
1) 데이터 분석과 데이터 과학
- 데이터 과학(data science)은 통계학(statistics), 데이터 분석, 머신러닝(machine learning), 데이터 마이닝(data mining) 등을 아우르는 큰 개념으로 볼 수 있다.
- 데이터 분석은 올바른 의사결정을 돕기 위한 통찰(insight)을 제공하는 데 초점을 맞추고, 데이터 과학은 한 걸음 더 나아가 문제 해결을 위한 최선의 솔루션(solution)을 만드는 데 초점을 둔다.
- 통계적 관점에서 보면 데이터 분석은 크게 세 가지로 나눌 수 있다.
| 기술 통계 | - 관측이나 실험을 통해 수집한 데이터를 정량화하거나 요약하는 기법 |
| 탐색적 데이터 분석 | - 데이터를 시각적으로 표현하여 주요 특징을 찾고 분석하는 방법 |
| 가설 검정 | - 주어진 데이터를 기반으로 특정 가정이 합당한지 평가하는 통계 방법 |
2. 데이터 분석을 위한 도구
1) 파이썬 필수 패키지
넘파이(numpy)
- 고성능 과학 계산과 다차원 배열(array)을 위한 파이썬 패키지
판다스(Pandas)
- 파이썬 데이터 분석을 위한 전문 패키지
- 판다스는 넘파이 배열과 다르게 엑셀의 시트처럼 숫자와 문자를 섞어서 표 형태로 저장할 수 있는 데이터프레임(DataFrame)을 사용
- 편리한 데이터 처리와 분석 작업을 위해 많은 기능을 제공
맷플롯립(matplotlib)
- 파이썬 데이터 시각화를 위한 기본 패키지
사이파이(SciPy)
- 넘파이를 기반으로 구축된 수학과 과학 계산 전문 패키지
- 미분,적분,확률,선형대수,최적화 등을 알고리즘으로 구현
사이킷런(scikit-learn)
- 파이썬의 머신러닝 패키지
3. 이 도서가 얼마나 인기가 좋을까요?
1) 코랩에서 데이터 확인하기
- CSV(comma-separated values)는 콤마(,)로 구분된 텍스트 파일이다.
- 한줄이 하나의 레코드(record)이며 레코드는 콤마로 구분된 여러 필드(filed)로 구성된다.
- 행(row)는 CSV 파일에서 한 줄로 표현된다. 열(column)은 콤마로 구분된다.
코랩에서 데이터 다운로드 하기 : gdown 패키지
import gdown
gdown.download('https://bit.ly/3eecMKZ',
'남산도서관 장서 대출목록 (2021년 04월).csv', quiet=False)

2) 파이썬으로 CSV 파일 출력하기
- csv 파일은 텍스트 파일이므로 파이썬의 open() 함수로 읽을 수 있다.
- with 문으로 파일을 연 다음 readline() 메서드로 파일에서 한 줄을 읽어서 출력
- 파이썬의 open() 함수는 기본적으로 텍스트 파일이 UTF-8 형식으로 저장되어 있다고 가정
파일 인코딩 형식 확인하기 : chardet.detect() 함수
- 파이썬에서 chardet.detect() 함수를 사용하면 문자 인코딩 방식을 알아낼 수 있다.
- mode 매개변수를 바이너리(binaray) 읽기 모드인 'rb'로 지정하고, 그 다음 chardet.detect() 함수에 데이터를 넣어 어떤 인코딩을 사용하는지 출력
import chardet
with open('남산도서관 장서 대출목록 (2021년 04월).csv', mode='rb') as f:
d = f.readline()
print(chardet.detect(d))

인코딩 형식 지정하기
- open() 함수로 파일을 읽을 때 encoding 매개변수로 인코딩 형식을 'EUC-KR'로 지정
with open('남산도서관 장서 대출목록 (2021년 04월).csv', encoding='euc-kr') as f:
print(f.readline())
print(f.readline())

3) 데이터프레임 다루기 : 판다스
- 판다스는 CSV 파일을 읽어 데이터프레임(DataFrame)이라는 표 형식 데이터(tabula data)로 저장
- 표 형식 데이터는 행과 열로 구성된 데이터 구조
- 시리즈(series)가 1차원 데이터라면 데이터 프레임은 2차원 데이터로 행과 열을 가지게 되는 데이터 구조
CSV 파일을 데이터프레임으로 읽기 : read_csv() 함수
- 판다스에서 CSV 파일을 읽을 때는 read_csv() 함수를 사용
- low_meomry 매개변수를 False로 지정하여 파일을 나누어 읽지 않고 한번에 읽기
import pandas as pd
df = pd.read_csv('남산도서관 장서 대출목록 (2021년 04월).csv', encoding='euc-kr',
low_memory=False)
- head() 메서드를 사용하면 데이터프레임의 처음 다섯 개 행을 확인할 수 있다.
df.head()
- 첫 번째 열은 데이터프레임의 인덱스(index)이다. 판다스는 행마다 0부터 시작하는 인덱스 번호를 자동으로 붙여 준다.
- CSV의 첫 번째 행은 열 이름으로 인식힌다.
- CSV 파일의 첫 행이 열 이름이 아니라면 read_csv() 함수를 호출할 때 header 매개변수를 None으로 지정해서 데이터 첫 행에 열 이름이 없다는 것을 알리고, names 매개변수에 열 이름 리스트를 따로 전달해준다.
데이터프레임을 CSV 파일로 저장하기 : to_csv() 메서드
- 판다스의 데이터프레임을 CSV로 저장할 때는 to_csv() 메서드를 사용한다.
- to_csv() 메서드는 기본적으로 UTF-8 형식으로 저장하기 때문에 나중에 open() 함수로 파일의 내용을 읽을 때 따로 encoding 매개변수를 사용하지 않아도 된다.
- to_csv() 메서드로 데이터 프레임을 ns_202104.csv 파일로 저장
df.to_csv('ns_202104.csv')
- 저장한 csv 파일을 다시 open() 함수로 확인
with open('ns_202104.csv') as f:
for i in range(3):
print(f.readline(), end='')
- 앞서 출력했던 CSV 파일과 다르게 CSV 파일 맨 위쪽에 데이터프레임에 있던 행 인덱스가 함께 저장됨
ns_df = pd.read_csv('ns_202104.csv', low_memory=False)
ns_df.head()
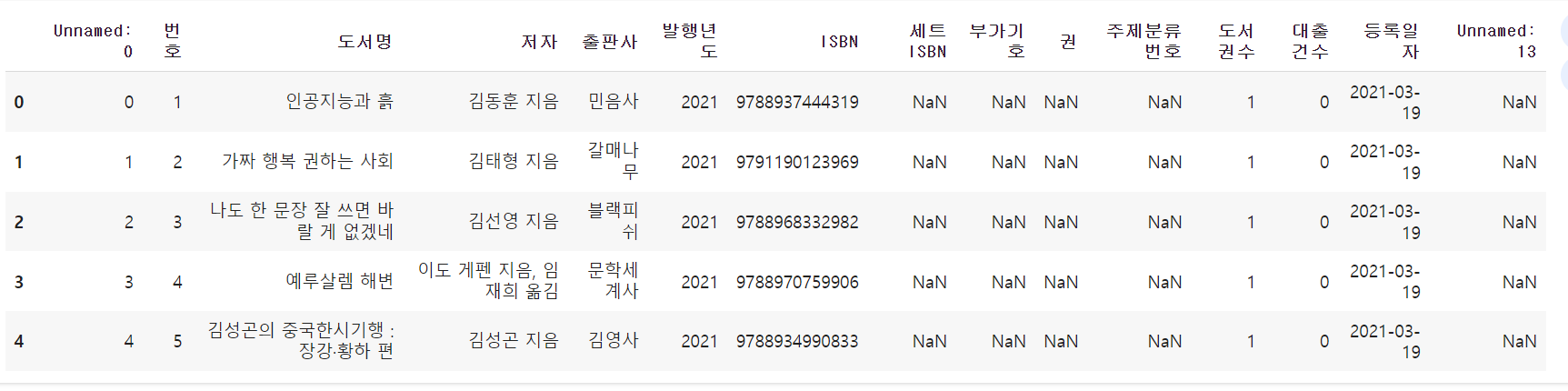
- 인덱스가 다시 생성되면서 'Unnammed:0'이라는 첫 번째 열과 중복된다.
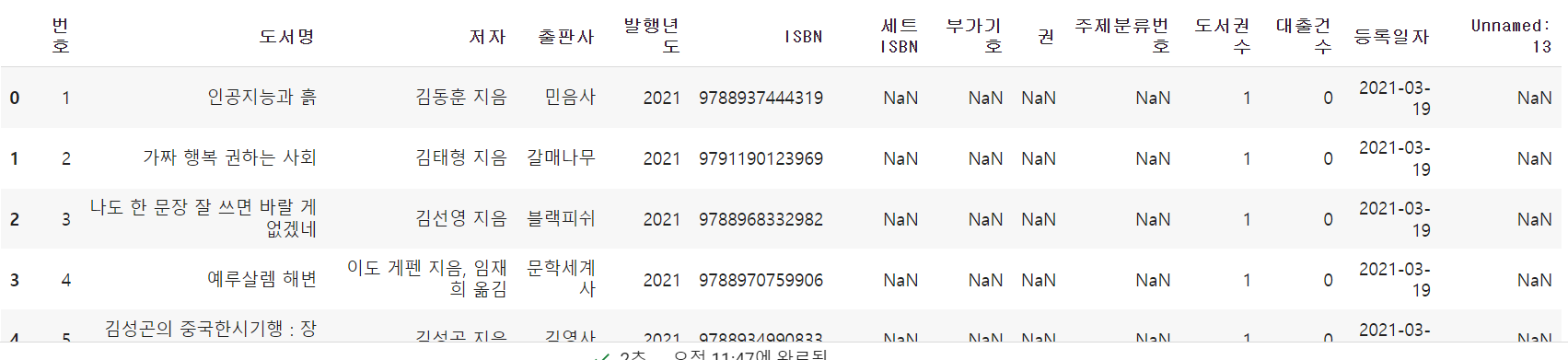
- CSV 파일에 인덱스가 이미 있다는 것을 알려 주려면 index_col 매개변수를 사용한다.
ns_df = pd.read_csv('ns_202104.csv', index_col=0, low_memory=False)
ns_df.head()
'데이터 > 데이터 분석' 카테고리의 다른 글
| [혼공] ch 6. 복잡한 데이터 표현하기 (0) | 2024.07.09 |
|---|---|
| [혼공] ch 5. 데이터 시각화하기 (0) | 2024.07.09 |
| [혼공] ch 4. 데이터 요약하기 (1) | 2024.07.05 |
| [혼공] ch 3. 데이터 정제하기 (0) | 2024.07.04 |
| [혼공] ch 2. 데이터 수집하기 (0) | 2024.07.03 |



