1. 불필요한 데이터 삭제하기
데이터 정제(data cleaning)
- 데이터에서 손상되거나 부정확한 부분을 수정하고, 불필요한 데이터를 삭제하거나 불완전한 값을 교체하는 등의 작업
- 데이터를 분석 목적에 맞게 변환하는 데이터 랭글링(data wrangling) 또는 데이터 먼징(data munging)의 일부로 수행될 수 있다.
1) 열 삭제하기
- gdown 패키지를 사용해 남산도서관 데이터를 다운로드
import gdown
gdown.download('https://bit.ly/3RhoNho', 'ns_202104.csv', quiet=False)
- 판다스 데이터프레임으로 읽어서 처음 다섯개 행을 출력
import pandas as pd
ns_df = pd.read_csv('ns_202104.csv', low_memory=False)
ns_df.head()

- 마지막 'Unnamed:13' 열을 삭제해야 함
- loc 메서드에 슬라이싱을 사용하면 '번호'열부터 '등록일자'열까지 선택하여 새로운 데이터프레임을 만들 수 있다.
ns_book = ns_df.loc[:,'번호':'등록일자']
ns_book.head()
loc 메서드와 불리언 배열
- colums 속성은 판다스의 Index 클래스 객체이다. 이 객체의 원소는 파이썬의 리스트처럼 숫자 인덱스로 참조할 수 있다.
print(ns_df.columns)
print(ns_df.columns[0])
- Index 클래스를 비롯하여 판다스 배열 성격의 객체는 어떤 값과 비교할 때 자동으로 배열에 있는 모든 원소와 하나씩 비교해준다. 이를 원소별 비교(element-wise comparison)라고 한다.
- 원소별 비교를 활용하여 ns_df.column에서 'Unnammed:13'열이 아닌 것을 표시하는 배열 만들기
ns_df.columns !='Unnamed: 13'
- 이를 selected_columns 변수에 저장하고 판다스 데이터프레임의 loc 메서드에 전달하면 True인 열의 행만 선택할 수 있다.
selected_columns = ns_df.columns != 'Unnamed: 13'
ns_book = ns_df.loc[:, selected_columns]
ns_book.head()
- 데이터프레임 중간에 있는 '부가기호'열 제외하기
selected_columns = ns_df.columns != '부가기호'
ns_book = ns_df.loc[:, selected_columns]
ns_book.head()

drop() 메서드
- 판다스에서는 데이터프레임의 행이나 열을 삭제하는 drop() 메서드를 제공한다.
- drop() 메서드로 열을 삭제하려면 첫 번째 매개변수에 삭제하려는 열 이름을 전달하고 axis 매개변수를 1로 지정한다.
ns_book = ns_df.drop('Unnamed: 13', axis=1)
ns_book.head()

- 불리언 배열을 사용하여 불필요한 열을 제외했던 것처럼 drop() 메서드도 중간에 있는 열을 간단하게 제외할 수 있다. 또한 첫 번째 매개변수에 제외한 열 이름을 리스트 형식으로 여러개 지정할 수도 있다.
ns_book = ns_df.drop(['부가기호','Unnamed: 13'], axis=1)
ns_book.head()

- drop() 메서드에 inplace 매개변수를 True로 지정하면 현재 선택한 데이터프레임을 바로 수정할 수 있다.
ns_book.drop('주제분류번호', axis=1, inplace=True)
ns_book.head()

dropna() 메서드
- 판다스는 비어있는 값을 NaN을 표시한다.
- dropna() 메서드는 기본적으로 NaN이 하나 이상 포함된 행이나 열을 삭제한다.
ns_book = ns_df.dropna(axis=1)
ns_book.head()

- 모든 값이 NaN인 열을 삭제하려면 dropna() 메서드에 how 매개변수를 'all'로 지정하면 된다.
ns_book = ns_df.dropna(axis=1, how='all')
ns_book.head()

2) 행 삭제하기
- 행을 삭제할 때도 drop() 메서드를 사용할 수 있다. axis 매개변수를 0으로 지정하면 행을 삭제할 수 있지만, 기본값이 0이기 때문에 생략 가능하다.
ns_book2 = ns_book.drop([0,1])
ns_book2.head()

[ ] 연산자와 슬라이싱
- 인덱스가 0,1인 행을 제외한 모든 행을 선택하기 위해 [ ] 연산자에 슬라이싱을 사용
ns_book2 = ns_book[2:]
ns_book2.head()

[ ] 연산자와 불리언 배열
- 불리언 배열을 사용해서 행을 선택
- 비교 연산자를 활용해 원하는 행은 True로 표시하고 제외할 행은 False로 표시한 불리언 배열을 만들어 사용
ex)
- 출판사가 '한빛미디어'인 행만 선택
selected_rows = ns_df['출판사'] == '한빛미디어'
ns_book2 = ns_book[selected_rows]
ns_book2.head()
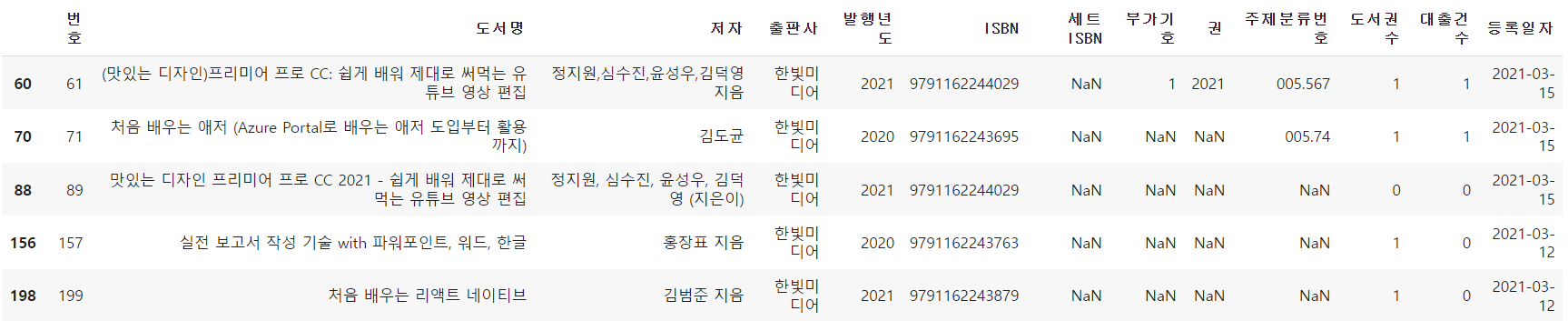
- 대출건수가 1,000 이하인 행을 모두 삭제하고 싶다면 ns_book['대출건수'] > 1000와 같이 조건을 넣어 대출건수가 1,000이 넘는 행을 선택하면 된다.
ns_book2 = ns_book[ns_book['대출건수'] > 1000]
ns_book2.head()

3) 중복된 행 찾기
- 판다스 데이터프레임의 중복된 행은 duplicated() 메서드를 사용하여 검사할 수 있다.
- 중복된 행 중에서 처음 행을 제외한 나머지 행은 True로, 그 외에 중복되지 않은 나머지 모든 행은 False로 표시한 불리언 배열을 반환한다.
- duplicated() 메서드는 기본적으로 데이터프레임에 있는 모든 열을 기준으로 중복된 행을 찾기
- 불필요한 열을 정리한 ns_book 데이터프레임에 중복된 행이 있는지 확인
sum(ns_book.duplicated())
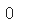
- 일부 열을 기준으로 중복된 행을 찾으려면 duplicated() 메서드의 subset 매개변수에 기준 열을 나열한다.
- '도서명','저자','ISBN'을 기준으로 중복된 행 찾기
sum(ns_book.duplicated(subset=['도서명','저자','ISBN']))

- duplicated() 메서드에 keep 매개변수를 False로 지정하여 중복된 행을 True로 표시
- keep=False는 중복된 행을 모두 True로 표시한 불리언 배열을 반환
dup_rows = ns_book.duplicated(subset=['도서명','저자','ISBN'], keep=False)
ns_book3 = ns_book[dup_rows]
ns_book3.head()
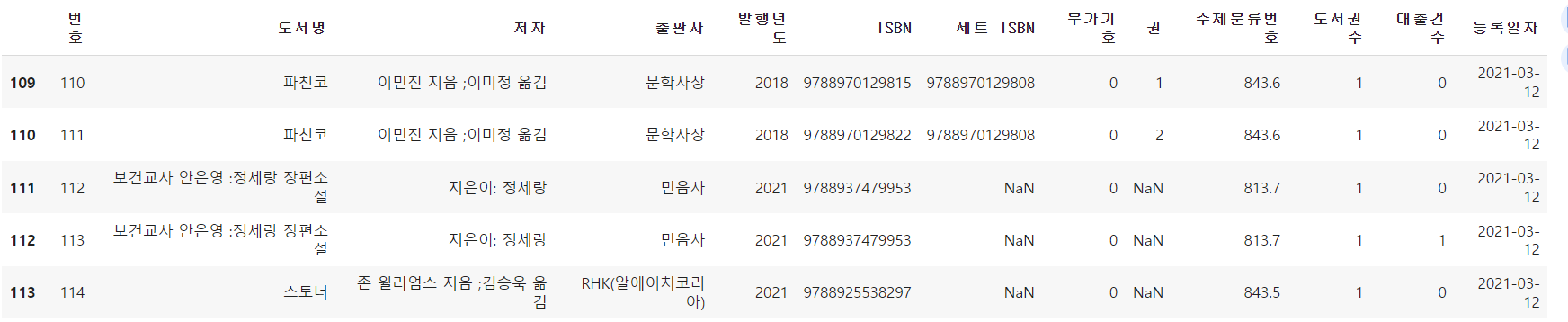
4) 그룹별로 모으기
- 앞으로 어떤 도서가 인기 있을지 예상하려고 하므로 이 데이터프레임에서 '대출건수' 열이 중요하다. 따라서 도서의 대출건수는 하나로 합치는 것이 좋다.
- groupby() 메서드 사용하여 도서별로 그룹 만들기
- groupby() 메서드의 by 매개변수에는 행을 합칠 때 기준이 되는 열을 지정한다.
- ns_book 데이터프레임에 있는 전체 열을 사용하는 대신, 그룹으로 묶을 기준 열과 '대출건수'열만 선택하여 사용
count_df = ns_book[['도서명','저자','ISBN','권','대출건수']]
- 결과를 반환한 count_df 데이터프레임에 groupby() 메서드를 적용한다. 같은 책의 대출건수는 하나로 합쳐야 하므로 sum() 메서드롤 사용한다.
- groupby() 메서드는 기본적으로 by 매개변수에 지정된 열에 NaN이 포함되어 있으면 해당 행을 삭제한다. count_df 데이터프레임의 '도서명'이나 '저자','권' 열에는 값이 누락되어 이따금 NaN이 포함되어 있다. NaN이 포함된 행을 삭제하고 계산하면 대출건수 합계에서 빠지기 때문에 이를 막기 위해 dropna 매개변수를 False로 지정한다.
loan_count = count_df.groupby(by=['도서명','저자','ISBN','권'], dropna=False).sum()
loan_count.head()
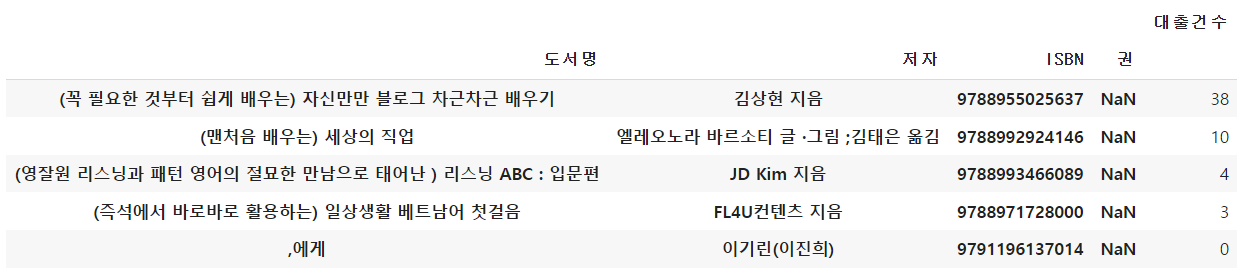
5) 원본 배열 업데이트하기
- 대출 건수를 원본 데이터프레임에 업데이트
- 그런데 원본 데이터프레임에는 중복된 데이터가 있다. 따라서 대출건수를 업데이트하기 전에 다음과 같은 과정을 거쳐야 한다.
- duplicated() 메서드로 중복된 행을 True로 표시한 불리언 배열을 만든다.
- 1번에서 구한 불리언 배열을 반전시켜서 중복되지 않은 고유한 행을 True로 표시한다.
- 2번에서 구한 불리언 배열을 사용해 원본 배열에서 고유한 행만 선택한다.
- 중복된 행을 True로 표시한 불리언 배열을 반전시킬 때는 판다스의 ~연산자를 사용한다. 그 다음 원본 배열에서 고유한 배열을 선택하여 copy() 메서드로 ns_book3 데이터프레임을 만든다.
dup_rows = ns_book.duplicated(subset=['도서명','저자','ISBN','권']) ## 중복된 행을 True로 표시
unique_rows = ~dup_rows ## 불리언 배열을 반전시켜 고유한 행을 True로 표시
ns_book3 = ns_book[unique_rows].copy() ## 고유한 행만 선택
sum(ns_book3.duplicated(subset=['도서명','저자','ISBN','권']))
원본 데이터프레임 인덱스 설정하기
- ns_book3의 인덱스를 loan_count 데이터프레임의 인덱스와 동일하게 만든다.
- 지정한 열을 인덱스로 설정할 때는 set_index() 메서드를 사용한다. 이때 inplace 매개변수를 True로 지정해 새로운 데이터프레임을 반환하지 않고 ns_book3 데이터프래임을 수정한다.
ns_book3.set_index(['도서명','저자','ISBN','권'], inplace=True)
ns_book3.head()

업데이트하기 : update() 메서드
- 다른 데이터프레임을 사용해 원본 데이터프레임의 값을 업데이트할 때는 update() 메서드를 사용한다
ns_book3.update(loan_count)
ns_book3.head()
- 업데이트가 제대로 되었다면 인덱스 열을 해제한다. reset_index() 메서드로 데이터프레임 인덱스를 재설정할 수 있다.
ns_book4 = ns_book3.reset_index()
ns_book4.head()

- 대출건수가 잘 합쳐졌는지 확인
- 원본 데이터프레임 ns_book에서 대출건수가 100회 이상인 책의 개수 세어보기
sum(ns_book['대출건수']>100)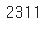
- 새로 만든 ns_book4 데이터프레임에서 대출건수가 100회 이상인 책의 개수 세어보기
sum(ns_book4['대출건수']>100)

- 대출건수가 100회 이상인 책들의 수가 늘어났다. 이는 중복된 도서의 대출건수를 합쳤기 때문이다.
- 그러나 여러개의 열을 사용해 데이터프레임의 인덱스를 만들었다가 다시 해체했기 때문에 초기 데이터프레임 열과 ns_book4 데이터프레임의 열 순서가 달라졌다.
- 열의 순서를 바꾸는 가장 간단한 방법은 [ ] 연산자에 원하는 열 이름을 순서대로 전달하는 것이다.
ns_book4 = ns_book4[ns_book.columns]
ns_book4.head()

2. 잘못된 데이터 수정하기
1) 데이터프레임 정보 요약 확인하기
import pandas as pd
ns_book4 = pd.read_csv('ns_book4.csv', low_memory=False)
ns_book4.head()

- info() 메서드를 사용하면 열마다 NaN이 아닌 값이 몇 개나 있는지 확인할 수 있다.
ns_book4.info()

2) 누락된 값 처리하기
누락된 값 개수 확인하기 : isna() 메서드
- isna() 메서드는 각 행이 비어 있는지를 나타내는 불리언 배열을 반환한다.
- 그리고 sum() 메서드를 이어서 호출하면 불리언 배열의 True 개수로 비어 있는 행 개수를 얻을 수 있다.
ns_book4.isna().sum()

누락된 값으로 표시하기 : None과 np.nan
- 판다스 데이터프레임에서는 정수를 저장하는 열에 파이썬의 None을 입력하면 누락된 값으로 인식한다.
- ns_book4 데이터프레임의 '도서권수' 열에 있는 첫 번째 행 값을 None으로 바꾼 후 '도서권수'열에 isna() 메서드를 적용해 누락된 값 세기
ns_book4.loc[0,'도서권수'] = None
ns_book4['도서권수'].isna().sum()
- 판다스는 NaN을 특별한 실수 값으로 저장한다. 그래서 원래 데이터 타입이 int64였던 '도서권수'열이 NaN을 표시하기 위해 float64로 자동으로 바뀐다.
ns_book4.head(2)

- '도서권수' 열의 첫 번째 행을 원래대로 1로 바꾸기 현재 데이터 타입이 실수형이므로 다시 정수형으로 바꾸어야 한다.
- '도서권수' 열과 함께 '대출건수' 열도 데이터 타입을 int32로 바꾸기
- 데이터 타입을 지정할 때는 astype() 메서드를 사용한다. 매개변수를 {열 이름:데이터 타입} 형식의 딕셔너리로 전달한다.
ns_book4.loc[0, '도서권수'] = 1
ns_book4 = ns_book4.astype({'도서권수':'int32', '대출건수': 'int32'})
ns_book4.head(2)

- 판다스는 NaN이라는 값을 따로 가지고 있지 않다. 대신 넘파이 패키지에 있는 np.nan을 사용해야 한다,
- 따라서 첫 번째 행의 '부가기호' 열의 값을 None에서 NaN으로 표시하려면 다음과 같이 np.nan을 사용한다.
import numpy as np
ns_book4.loc[0, '부가기호'] = np.nan
ns_book4.head(2)

누락된 값 바꾸기(1) : loc, fillna() 메서드
- '세트 ISBN' 열은 대부분 비어 있는데, 이 누락된 값을 NaN이 아니라 빈 문자열(' ')로 바꾸기
- loc 메서드를 사용하면 누락된 값을 원하는 값으로 바꿀 수 있다. 그러려면 누락된 값을 가리키는 불리언 배열을 만들어야 하는데, 누락된 값을 확인하는 isna() 메서드로 간단하게 만들 수 있다.
set_isbn_na_rows = ns_book4['세트 ISBN'].isna() ##누락된 값을 찾아 불리언 배열로 반환
ns_book4.loc[set_isbn_na_rows, '세트 ISBN'] = '' ##누락된 값을 빈 문자열로 바꾼다.
ns_book4['세트 ISBN'].isna().sum() ##누락된 값이 몇 개인지 센다.
- '세트 ISBN' 열의 NaN을 모두 빈 문자열로 바꾸었기 떄문에 누락된 행의 개수는 0이다.
- 조금 더 편리한 방법은 fillna() 메서드에 원하는 값을 전달하면 NaN을 대체할 수 있다.
- ns_book4에 있는 모든 NaN을 '없음' 문자열로 바꾸기
ns_book4.fillna('없음').isna().sum()

- NaN이 모두 '없음' 문자열로 바뀌어 NaN 개수를 세면 0이 출력된다.
- 특정 열만 선택해서 NaN을 바꿀 수도 있다. 하지만 특정 열을 선택한 후 fillna() 메서드를 적용하면 열 이름 없이 개수만 있는 판다스 시리즈 객체로 반환한다.
ns_book4['부가기호'].fillna('없음').isna().sum() #부가기호 열만 선택
- '부가기호' 열을 NaN을 바꾸면서 전체 데이터프레임을 반환하려면 다음처럼 열 이름과 바꾸려는 값으로 이루어진 딕셔너리로 전달하면 된다.
ns_book4.fillna({'부가기호':'없음'}).isna().sum()

누락된 값 바꾸기(2) : replace() 메서드
- replace() 메서드는 NaN은 물론 어떤 값도 바꿀 수 있는 편리한 메서드이다.
1. 바꾸려는 값이 하나일 때
replace(원래 값, 새로운 값)
- 원래 값에 np.nan을 전달하여 NaN을 '없음'으로 바꾸기
ns_book4.replace(np.nan,'없음').isna().sum()

2. 바꾸려는 값이 여러 개일 때
- 바꾸는 값이 여러 개일 때는 리스트 형식으로 전달한다.
replace([원래값1, 원래값2],[새로운 값1, 새로운 값2])
- NaN을 '없음'으로 바꾸고 '2021' 문자열을 '21'로 바꾸기
ns_book4.replace([np.nan, '2021'], ['없음', '21']).head(2)

- 리스트 대신 ({원래 값1 : 새로운 값1, 원래 값2: 새로운 값2})처럼 딕셔너리 형식으로도 전달할 수 있다.
ns_book4.replace({np.nan: '없음', '2021': '21'}).head(2)

3. 열 마다 다른 값으로 바꿀 떄
- 열 이름과 바꾸려는 값을 딕셔너리 형식으로 전달하여 열마다 다른 값을 바꿀 수 있다.
replace({열 이름:원래 값},{새로운 값)
- '부가기호' 열의 NaN을 '없음'으로 바꾸면 다음과 같다.
ns_book4.replace({'부가기호': np.nan}, '없음').head(2)

3) 정규 표현식
- 정규 표현식(regular expression) 또는 줄여서 정규식은 문자열 패턴을 찾아서 대체하기 위한 규칙의 모음이다.
숫자 찾기 : \d
- 정규 표현식에서 숫자를 나타내는 기호는 \d 이다.
- 네 자리 연도에 해당하는 표현은 \d\d\d\d이다.
- 표현식을 그룹으로 묶을 때는 괄호를 사용한다. 뒤에 두 자리만 하나의 그룹으로 묶을 때는 \d\d(\d\d)처럼 쓴다.
- 패턴에 맞는 문자열을 찾은 후 첫 번째 그룹에 해당하는 뒷자리 연도 두 개를 추출한다. 패턴 안에 있는 그룹을 나타낼 때는 \1, \2 처럼 사용한다. 그룹의 번호는 패턴 안에 등장하는 순서대로 매겨진다.
- '발행년도' 열의 값을 정규 표현식으로 두 자리 연도로 바꾸기
- 정규 표현식을 사용한다는 의미로 regex 매개변수 옵션을 True로 지정한다.
- 이때 정규 표현식 앞에 붙인 r 문자는 파이썬에서 정규 표현식을 다른 문자열과 구분하기 위해 접두사처럼 붙인다.
ns_book4.replace({'발행년도': {r'\d\d(\d\d)': r'\1'}}, regex=True)[100:102]

- 정규 표현식이 반복될 때는 일일이 쓰는 대신 다음과 같이 중괄호를 사용하여 개수를 지정할 수있다.
- 예를 들어 \d{2}는 \d\d와 동일하게 연속된 숫자 두 개를 의미한다.
ns_book4.replace({'발행년도': {r'\d{2}(\d{2})': r'\1'}}, regex=True)[100:102]
문자 찾기 : 마침표(.)
- (지은이), (옮긴이) 문자열 삭제
- 어떤 문자에도 대응하는 정규 표현식 문자는 마침표(.) 이다.
- *문자를 사용하여 0개이상 반복된다고 표시할 수 있다.
- 정규표현식에서 괄호는 그룹을 나타내는 데 사용하므로 일반 문자라고 인식하게 하려면 역슬래시(\)를 앞에 붙여야 한다.
- 띄어쓰기가 있으므로 공백 문자를 나타내는 정규 표현식 \s를 앞에 붙인다.
ns_book4.replace({'저자': {r'(.*)\s\(지은이\)(.*)\s\(옮긴이\)': r'\1\2'},
'발행년도': {r'\d{2}(\d{2})': r'\1'}}, regex=True)[100:102]

4) 잘못된 값 바꾸기
- '발행년도' 열에서 숫자가 아닌 문자를 포함하는 모든 행을 찾기
- contains() 메서드의 na 매개변수를 True를 지정하여 연도가 누락된 행을 True로 표시
- 만약 '발행년도' 열에 누락된 값이 있다면 contains()메서드는 기본적으로 np.nan으로 채워서 invalid_number 배열을 인덱싱에 사용할 수 없기 때문이다.
invalid_number = ns_book4['발행년도'].str.contains('\D', na=True)
print(invalid_number.sum())
ns_book4[invalid_number].head()
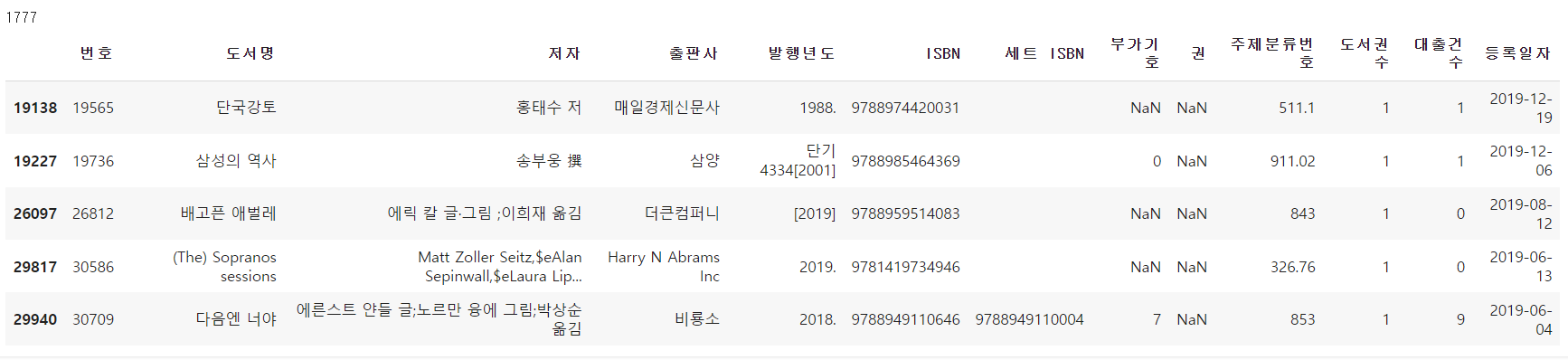
- 정규 표현식을 사용하여 연도 앞과 뒤에 있는 문자를 제외
- 연도를 나타내는 숫자 네 개는 \d[4]이고 이 숫자는 그룹으로 묶어 \1로 참조한다.
- 그리고 숫자 앞 뒤에 어떤 문자가 나오더라도 모두 매칭하기 위해 .*를 사용한다.
ns_book5 = ns_book4.replace({'발행년도':r'.*(\d{4}).*'}, r'\1', regex=True)
ns_book5[invalid_number].head()
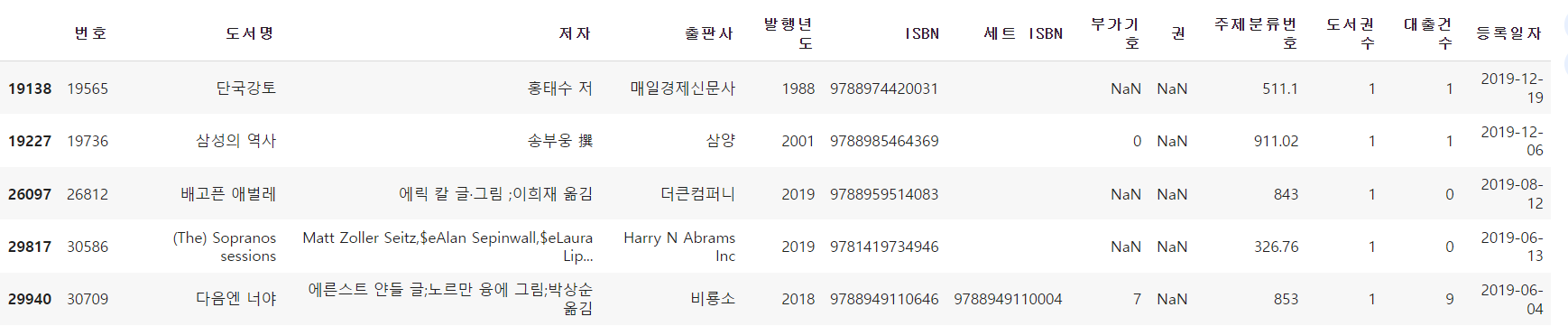
- 숫자 이외의 문자가 들어간 행의 개수와 데이터 확인
unkown_year = ns_book5['발행년도'].str.contains('\D', na=True)
print(unkown_year.sum())
ns_book5[unkown_year].head()

- 1,777개에서 67개로 줄었다. 이제 변환되지 않은 값은 NaN이거나 네 자리 숫자가 아닌 값이다.
- 이런 값은 어떻게 변환할지 알 수 없기 때문에 임의로 -1 값으로 바꾼다음 astype() 메서드로 '발행년도'의 데이터 타입을 정수형인 int32로 변환한다.
ns_book5.loc[unkown_year, '발행년도'] = '-1'
ns_book5 = ns_book5.astype({'발행년도': 'int32'})
- 연도 중 이상하게 아주 큰 값이나 작은 값이 들어 있는 경우가 있다.
- 연도가 4000년이 넘는 경우를 확인. gt() 메서드는 전달된 값보다 큰 값을 찾는다.
ns_book5['발행년도'].gt(4000).sum()
- 4000년이 넘는 연도에서 2333을 뺴서 서기로 바꾼 다음 연도가 4,000년이 넘는 도서가 있는지 확인
dangun_yy_rows = ns_book5['발행년도'].gt(4000)
ns_book5.loc[dangun_yy_rows, '발행년도'] = ns_book5.loc[dangun_yy_rows, '발행년도'] - 2333
dangun_year = ns_book5['발행년도'].gt(4000)
print(dangun_year.sum())
ns_book5[dangun_year].head(2)

- 연도가 이상하게 높은 도서가 13권이나 된다. 이런 도서도 모두 -1로 표시
ns_book5.loc[dangun_year, '발행년도'] = -1
- 마지막으로 연도가 작은 값 확인. 0보다 크고 1900년도 이전의 도서 찾기
old_books = ns_book5['발행년도'].gt(0) & ns_book5['발행년도'].lt(1900)
ns_book5[old_books]
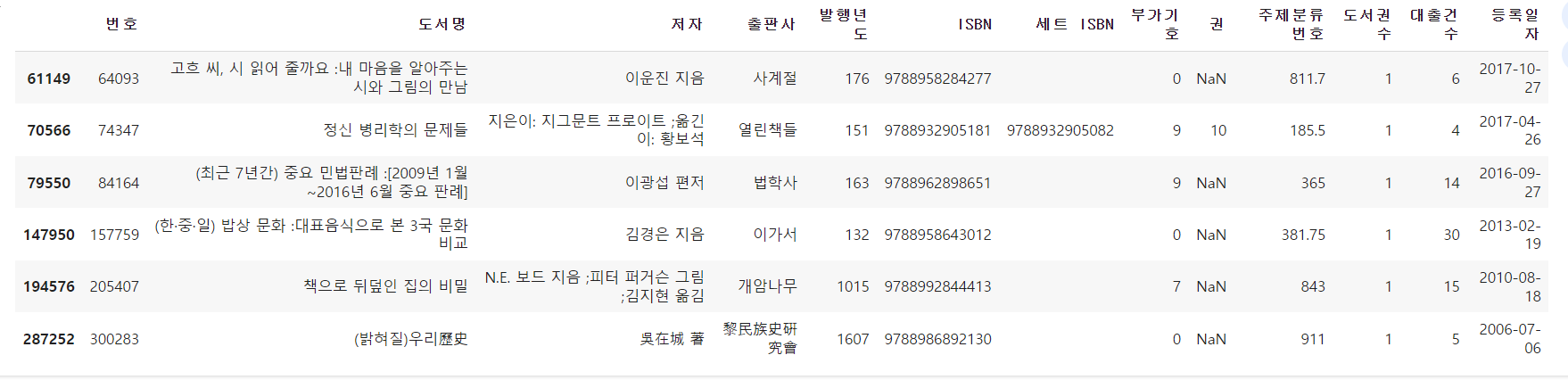
- 이 도서를 연도를 -1로 설정하고 전체 행 개수를 확인
ns_book5.loc[old_books, '발행년도'] = -1
ns_book5['발행년도'].eq(-1).sum()

5) 누락된 정보 채우기
- '도서명','저자','출판사' 열에는 누락된 값이 있으면 안된다. 그러므로 누락된값이 있거나 '발행년도'열이 -1인 행의 개수 확인
na_rows = ns_book5['도서명'].isna() | ns_book5['저자'].isna() \
| ns_book5['출판사'].isna() | ns_book5['발행년도'].eq(-1)
print(na_rows.sum())
ns_book5[na_rows].head(2)

- 뷰티플수프를 사용해 이런 값을 채워보기
import requests
from bs4 import BeautifulSoup
- 도서명을 가져오는 함수
def get_book_title(isbn):
# Yes24 도서 검색 페이지 URL
url = 'http://www.yes24.com/Product/Search?domain=BOOK&query={}'
# URL에 ISBN을 넣어 HTML 가져옵니다.
r = requests.get(url.format(isbn))
soup = BeautifulSoup(r.text, 'html.parser') # HTML 파싱
# 클래스 이름이 'gd_name'인 a 태그의 텍스트를 가져옵니다.
title = soup.find('a', attrs={'class':'gd_name'}) \
.get_text()
return title
- 작성한 get_book_title() 함수를 '골목의 시간을 그리다' 책의 ISBN으로 테스트
get_book_title(9791191266054)

- 같은 방식으로 저자, 출판사, 발행 연도를 추출하여 반환하는 함수 만들기
- 도서명과 달리 저자는 두 명 이상일 수 있기 때문에 뷰티플수프의 find_all() 메서드를 사용해 저자를 담은 <a> 태그를 모두 추출
- 리스트 안에 for문을 사용하는 리스트 내포로 <a> 태그에 속한 모든 텍스트를 파이썬 리스트에 저장
- 그 다음 추출한 결과를 join() 메서드를 사용해 하나의 문자열로 합쳐준다.
- 발행 연도는 '2020년 12월'처럼 쓰여 있으므로 정규식을 사용하여 연도만 추출해야 한다. 파이썬에서 정규표현식을 지원하는 re 모듈의 findall() 함수를 사용하면 원하는 정규식에 매칭되는 모든 문자열을 찾아 리스트로 반환해준다.
import re
def get_book_info(row):
title = row['도서명']
author = row['저자']
pub = row['출판사']
year = row['발행년도']
# Yes24 도서 검색 페이지 URL
url = 'http://www.yes24.com/Product/Search?domain=BOOK&query={}'
# URL에 ISBN을 넣어 HTML 가져옵니다.
r = requests.get(url.format(row['ISBN']))
soup = BeautifulSoup(r.text, 'html.parser') # HTML 파싱
try:
if pd.isna(title):
# 클래스 이름이 'gd_name'인 a 태그의 텍스트를 가져옵니다.
title = soup.find('a', attrs={'class':'gd_name'}) \
.get_text()
except AttributeError:
pass
try:
if pd.isna(author):
# 클래스 이름이 'info_auth'인 span 태그 아래 a 태그의 텍스트를 가져옵니다.
authors = soup.find('span', attrs={'class':'info_auth'}) \
.find_all('a')
author_list = [auth.get_text() for auth in authors]
author = ','.join(author_list)
except AttributeError:
pass
try:
if pd.isna(pub):
# 클래스 이름이 'info_auth'인 span 태그 아래 a 태그의 텍스트를 가져옵니다.
pub = soup.find('span', attrs={'class':'info_pub'}) \
.find('a') \
.get_text()
except AttributeError:
pass
try:
if year == -1:
# 클래스 이름이 'info_date'인 span 태그 아래 텍스트를 가져옵니다.
year_str = soup.find('span', attrs={'class':'info_date'}) \
.get_text()
# 정규식으로 찾은 값 중에 첫 번째 것만 사용합니다.
year = re.findall(r'\d{4}', year_str)[0]
except AttributeError:
pass
return title, author, pub, year
- 이 함수는 누락된 값에만 뷰티플수프로 추출한 값을 저장한다. 만약 뷰티플수프로 추출할 수 없는 경우에는 오류가 발생한다. 따라서 오류 때문에 함수 실행이 종료되지 않고 이어서 다음 요소를 추출하도록 try ~ except문으로 예외 처리를 해주었다.
- 누락된 값이 있었던 처음 두 개의 행에 방금 작성한 get_book_info() 함수를 적용
- 함수가 여러 개의 값을 반환하는 경우 apply() 메서드는 기본적으로 반환된 값을 하나의 튜플로 만든다.
- 따라서 result_type 매개변수를 'expand'로 지정하여 반환된 값을 각기 다른 열로 만든다.
updated_sample = ns_book5[na_rows].head(2).apply(get_book_info,
axis=1, result_type ='expand')
updated_sample

gdown.download('http://bit.ly/3UJZiHw', 'ns_book5_update.csv', quiet=False)
ns_book5_update = pd.read_csv('ns_book5_update.csv', index_col=0)
ns_book5_update.head(
- ns_book5 데이터프레임을 ns_book5_update 데이터프레임 데이터로 업데이트한 후 누락된 행이 몇 개인지 다시 확인
ns_book5.update(ns_book5_update)
na_rows = ns_book5['도서명'].isna() | ns_book5['저자'].isna() \
| ns_book5['출판사'].isna() | ns_book5['발행년도'].eq(-1)
print(na_rows.sum())

- 누락된 값이 있는 행은 4,615개로 뷰티플수프로 데이터를 채우기 전보다 653개가 줄었다.
- 이제 마지막으로 누락된 값을 가진 행을 삭제하여 분석 대상에서 제외
ns_book5 = ns_book5.astype({'발행년도': 'int32'})
ns_book6 = ns_book5.dropna(subset=['도서명','저자','출판사'])
ns_book6 = ns_book6[ns_book6['발행년도'] != -1]
ns_book6.head()

- dropna() 메서드에 '도서명','저자','출판사'열을 리스트로 지정한 후 누락된 값이 있는 행을 삭제하고 그 다음 '발행년도' 열 값이 -1이 아닌 행만 선택하여 ns_book6 데이터프레임을 생성
ns_book5 = ns_book5.astype({'발행년도': 'int32'})
ns_book6 = ns_book5.dropna(subset=['도서명','저자','출판사'])
ns_book6 = ns_book6[ns_book6['발행년도'] != -1]
ns_book6.head()

'데이터 > 데이터 분석' 카테고리의 다른 글
| [혼공] ch 6. 복잡한 데이터 표현하기 (0) | 2024.07.09 |
|---|---|
| [혼공] ch 5. 데이터 시각화하기 (0) | 2024.07.09 |
| [혼공] ch 4. 데이터 요약하기 (1) | 2024.07.05 |
| [혼공] ch 2. 데이터 수집하기 (0) | 2024.07.03 |
| [혼공] ch 1. 데이터 분석을 시작하며 (1) | 2024.07.03 |



